Optimization for Modern LLM Online Serving: Continuous Batching and Paged Attention
Optimization for Modern LLM Online Serving: Continuous Batching and Paged Attention
不知不觉🕊了有点久,本次我们盘点一下面向大模型的服务系统(引擎)的设计相比于一些传统的机器学习服务系统的改进:
Continuous Batching
The compute utilization in serving LLMs can be improved by batching multiple requests. Because the requests share the same model weights, the overhead of moving weights is amortized across the requests in a batch, and can be overwhelmed by the computational overhead when the batch size is sufficiently large. However, batching the requests to an LLM service is non-trivial for two reasons. First, the requests may arrive at different times. A naive batching strategy would either make earlier requests wait for later ones or delay the incoming requests until earlier ones finish, leading to significant queueing delays. Second, the requests may have vastly different input and output lengths. A straightforward batching technique would pad the inputs and outputs of the requests to equalize their lengths, wasting GPU computation and memory.
To address this problem, fine-grained batching mechanisms, such as cellular batching and iteration-level scheduling , have been proposed. Unlike traditional methods that work at the request level, these techniques operate at the iteration level. After each iteration, completed requests are removed from the batch, and new ones are added. Therefore, a new request can be processed after waiting for a single iteration, not waiting for the entire batch to complete. Moreover, with special GPU kernels, these techniques eliminate the need to pad the inputs and outputs. By reducing the queueing delay and the inefficiencies from padding, the fine-grained batching mechanisms significantly increase the throughput of LLM serving.
Continuous batching is a technique used to optimize the performance of large language models (LLMs) by improving the efficiency of their inference. It is a system-level optimization that can produce 10 times or more difference in actual workloads. The technique is also known as dynamic batching or batching with iteration-level scheduling.
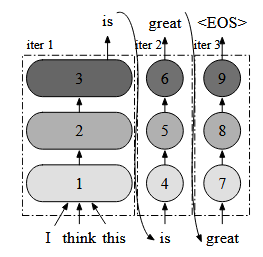
In traditional static batching, the batch size remains constant throughout the inference process. However, LLMs have an iterative inference process, which means that the length of the generated sequence is not known beforehand. This leads to underutilization of the GPU’s processing power and memory bandwidth. Continuous batching solves this problem by dynamically adjusting the batch size based on the length of the generated sequence. This allows the GPU to process more sequences in parallel, leading to higher throughput and lower latency.
Continuous batching is implemented using a technique called iteration-level scheduling. In this technique, the GPU processes multiple sequences in parallel, but each sequence is processed iteratively. The batch size is adjusted dynamically based on the length of the generated sequence. This allows the GPU to process more sequences in parallel, leading to higher throughput and lower latency.
The following LaTeX formula shows how the length of the generated sequence is used to adjust the batch size:
$$
batch_size = \frac{max_batch_size}{1 + \frac{length}{iteration_size}}
$$
where max_batch_size is the maximum batch size, length is the length of the generated sequence, and iteration_size is the number of iterations required to generate the sequence.
Continuous batching is a powerful optimization technique that can significantly improve the performance of LLMs. It is widely used in modern LLM inference systems and has become an essential tool for ML engineers working with large language models.
Paged Attention
Paged Attention is an attention algorithm that is inspired by the classical virtual memory and paging techniques in operating systems. It is used to manage memory efficiently in large language models (LLMs) serving systems.
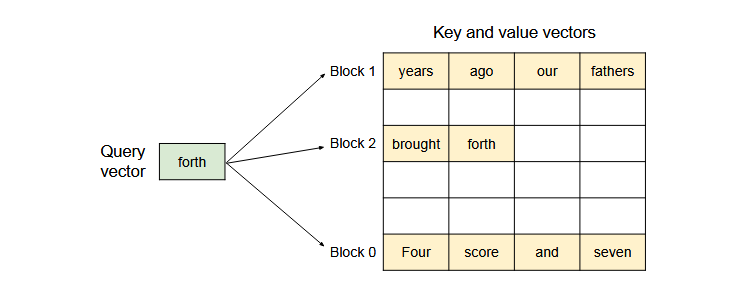
The key-value cache (KV cache) memory for each request in LLMs serving systems is huge and grows and shrinks dynamically. When managed inefficiently, this memory can be significantly wasted by fragmentation and redundant duplication, limiting the batch size. Paged Attention addresses this problem by allowing non-contiguous storage of contiguous KV tensors. It divides the KV cache of each sequence into blocks, each containing a fixed number of tokens. During attention calculation, it can efficiently locate and retrieve those blocks.
On top of Paged Attention, vLLM is built, which is an LLM serving system that achieves near-zero waste in KV cache memory and flexible sharing of KV cache within and across requests to further reduce memory usage. vLLM improves the throughput of popular LLMs by 2-4 × with the same level of latency compared to the state-of-the-art systems, such as FasterTransformer and Orca